
Cách đo lường chính xác một hệ thống (blockchain) là một trong những bước ít được nói đến nhất nhưng lại quan trọng nhất trong quá trình thiết kế và đánh giá hệ thống đó. Có rất nhiều giao thức đồng thuận và các biến thể với nhiều sự đánh đổi về hiệu suất cùng với khả năng mở rộng. Nhưng cho đến nay, vẫn chưa có phương pháp đáng tin cậy, được thống nhất trên toàn cầu cho phép so sánh apples to apples. Trong bài đăng này sẽ phác thảo một phương pháp lấy cảm hứng từ các phép đo trong các hệ thống trung tâm dữ liệu và thảo luận về các lỗi phổ biến cần tránh khi đánh giá mạng blockchain.

Các số liệu chính và tương tác của chúng
Hai số liệu quan trọng cần được tính đến khi phát triển hệ thống blockchain chính là độ trễ và thông lượng.
Điều đầu tiên mà người dùng quan tâm là độ trễ của giao dịch hoặc khoảng thời gian từ khi bắt đầu giao dịch/thanh toán đến khi nhận được xác nhận rằng giao dịch đó hợp lệ (ví dụ: họ có đủ tiền). Trong các hệ thống BFT cổ điển (ví dụ: PBFT, Tendermint, Tusk & Narwhal, v.v.), một giao dịch được hoàn tất sau khi được xác nhận, trong khi ở longest-chain consensus (ví dụ Nakamoto consensus, Solana/Ethereum PoS), một giao dịch có thể được đưa vào một block và sau đó reorged. Do đó phải đợi cho đến khi giao dịch ở mức “k-block deep”, dẫn đến độ trễ lớn hơn đáng kể so với một lần xác nhận.
Thứ hai, thông lượng của hệ thống thường quan trọng đối với các nhà thiết kế hệ thống. Đây là tổng tải mà hệ thống xử lý trên một đơn vị thời gian, thường được biểu thị bằng giao dịch trên giây.
Thoạt nhìn, hai chỉ số chính này dường như là nghịch đảo của nhau. Bởi vì thông lượng được đo bằng giao dịch mỗi giây và độ trễ được đo bằng giây, nên đương nhiên chúng ta mong đợi rằng Throughput = Load/ Latecy.
Điều này, tuy nhiên, không phải là trường hợp. Việc thực hiện này rất khó vì nhiều hệ thống có xu hướng tạo ra các biểu đồ hiển thị thông lượng hoặc độ trễ trên trục y với một số thứ như số lượng node trên trục x. Thay vào đó, một biểu đồ tốt hơn để tạo là biểu đồ thông lượng/độ trễ, làm cho nó rõ ràng bằng cách không linear.
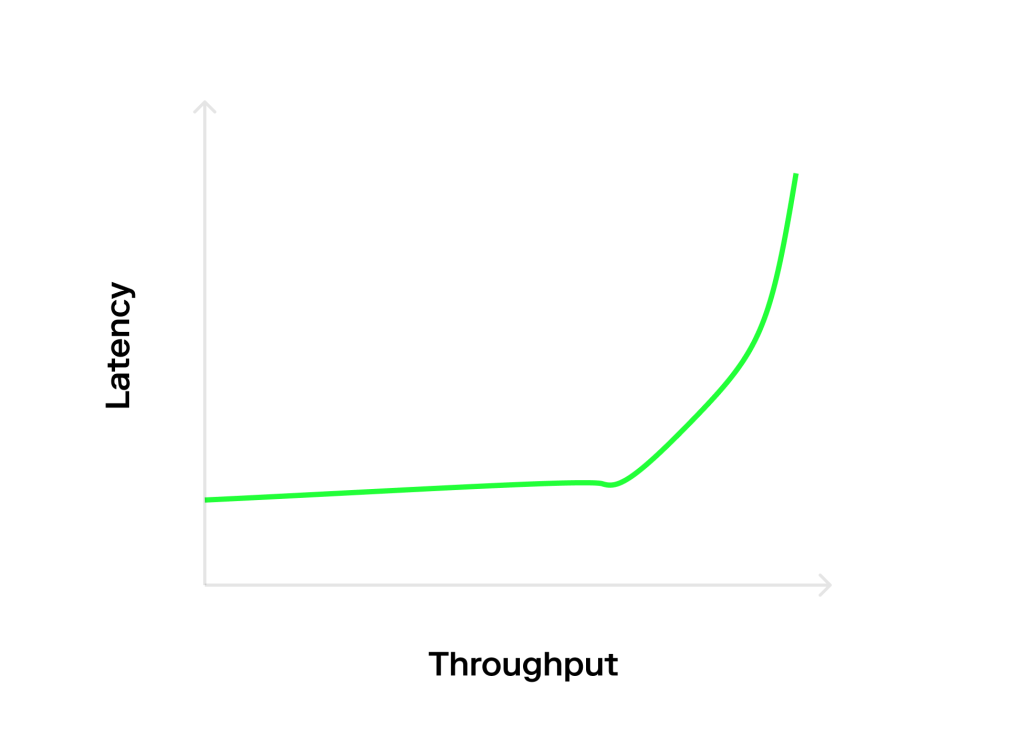
Khi có ít xung đột, độ trễ không đổi và thông lượng có thể thay đổi đơn giản bằng cách thay đổi load. Điều này xảy ra do có một chi phí tối thiểu cố định để thực hiện một giao dịch và độ trễ của hàng đợi bằng 0 ở mức độ tranh chấp thấp, làm cho bất cứ thứ gì đến đều sẽ xuất hiện trực tiếp.
Ở mức độ cạnh tranh cao, thông lượng không đổi, nhưng độ trễ có thể thay đổi chỉ bằng cách thay đổi load.
Điều này là do hệ thống đã quá tải và việc thêm tải sẽ khiến hàng đợi tăng lên vô tận. Ngược lại hơn nữa, độ trễ dường như thay đổi theo thời lượng thử nghiệm. Đây là một tạo tác của hàng đợi phát triển vô tận.
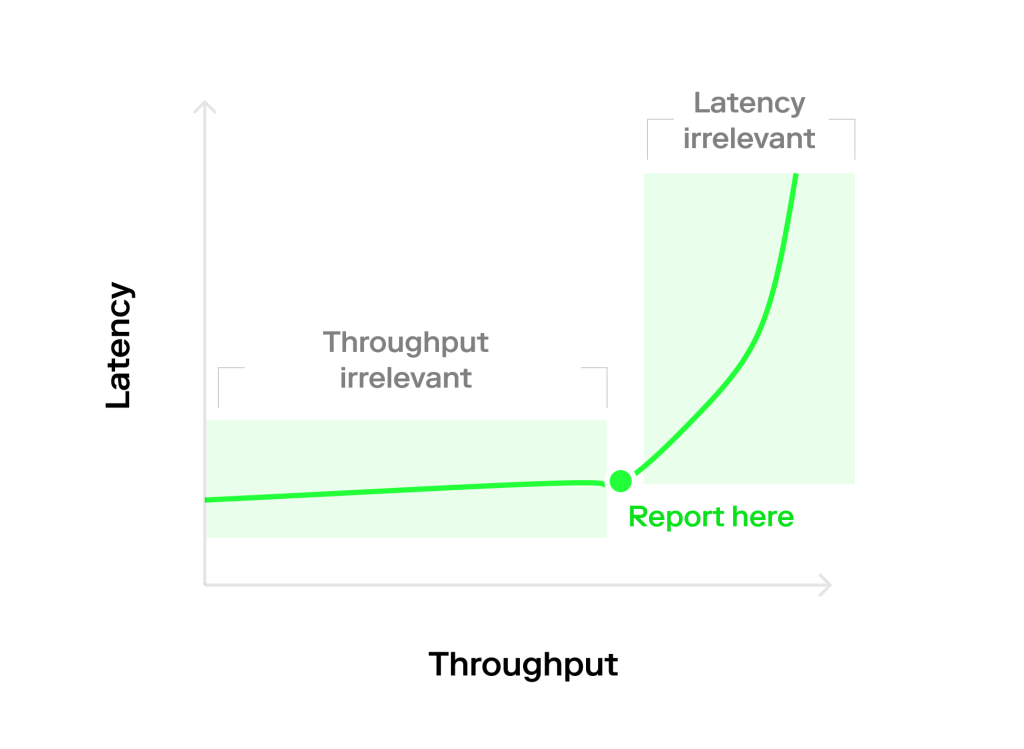
Tất cả những điều này có thể nhìn thấy trên “đồ thị hockey stick” hoặc “đồ thị chữ L” cổ điển, tùy thuộc vào sự phân bố giữa các đối thủ. Do đó, điểm mấu chốt rút ra từ bài viết rằng ta nên đo lường ở hot zone, nơi mà cả thông lượng và độ trễ đều ảnh hưởng đến điểm chuẩn của chúng ta, thay vì ở các cạnh, vì nơi đó chỉ có một trong hai vấn đề quan trọng.
Phương pháp đo lường
Khi tiến hành thí nghiệm, có ba phương án thiết kế chính:
- Vòng lặp mở và đóng
Có hai phương pháp chính để kiểm soát luồng yêu cầu đến mục tiêu. Một hệ thống vòng lặp mở được mô hình hóa bởi n = ∞ khách hàng gửi yêu cầu đến mục tiêu theo tỷ lệ λ và phân phối giữa các lần đến, ví dụ: Poisson. Hệ thống vòng kín giới hạn số lượng yêu cầu chưa xử lý tại bất kỳ thời điểm nào. Sự khác biệt giữa hệ thống vòng lặp mở và đóng là đặc điểm của một triển khai cụ thể và cùng một hệ thống có thể được triển khai trong các tình huống khác nhau. Chẳng hạn, một kho lưu trữ key-value có thể phục vụ hàng nghìn máy chủ ứng dụng trong triển khai vòng lặp mở hoặc chỉ một vài máy khách blocking trong triển khai vòng lặp kín.
Việc kiểm tra kịch bản chính xác là điều cần thiết bởi vì, trái ngược với các hệ thống vòng kín, thường có độ trễ bị hạn chế bởi số lượng yêu cầu chưa xử lý tiềm năng, các hệ thống vòng mở có thể tạo ra hàng đợi đáng kể và do đó, độ trễ dài hơn. Nói chung, các giao thức blockchain có thể được sử dụng bởi bất kỳ số lượng khách hàng nào và được đánh giá chính xác hơn trong môi trường vòng lặp mở.
- Phân phối các điểm chuẩn cho điểm chuẩn tổng hợp
Một câu hỏi thường gặp khi tạo khối lượng công việc tổng hợp là cách gửi yêu cầu. Nhiều hệ thống tải trước các giao dịch khi phép đo bắt đầu, nhưng điều này làm sai lệch các phép đo vì hệ thống bắt đầu ở trạng thái bất thường là 0. Hơn nữa, các yêu cầu được tải trước đã có trong bộ nhớ chính và do đó bỏ qua mạng stack.
Cách tiếp cận tốt hơn một chút sẽ là gửi yêu cầu với tốc độ xác định (ví dụ: 1000 TPS). Điều này sẽ dẫn đến biểu đồ hình chữ L (màu cam) vì có cách sử dụng tối ưu công suất của hệ thống.
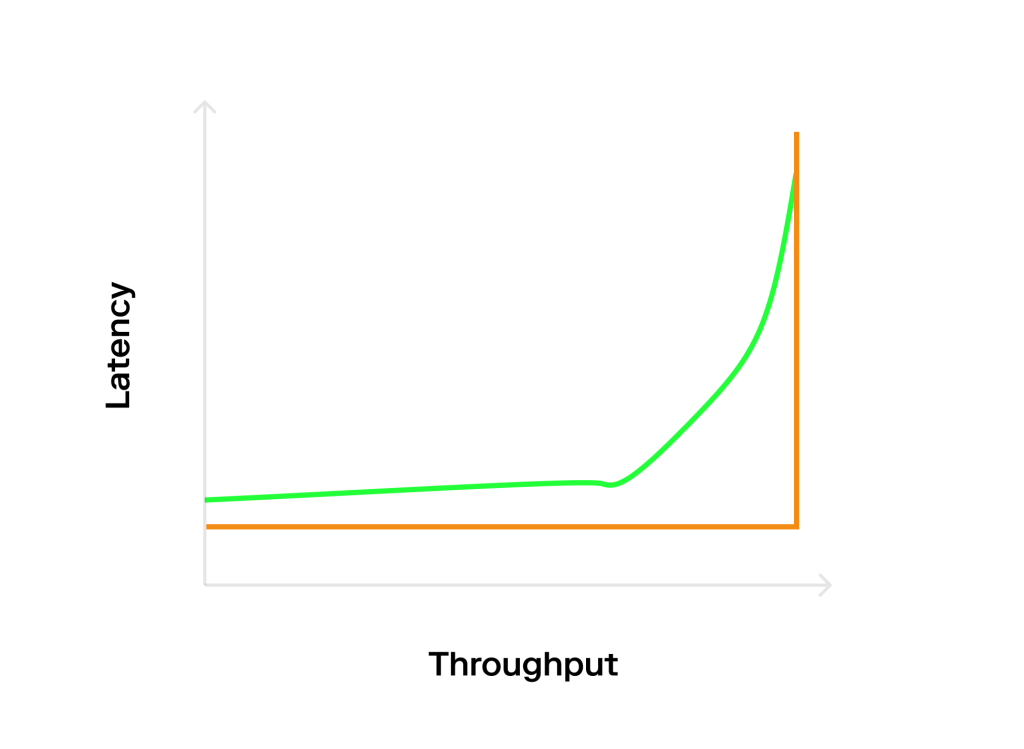
Tuy nhiên, các hệ thống mở thường không hành động theo cách có thể dự đoán được như vậy. Thay vào đó, chúng có các khoảng thời gian tải cao và thấp. Để mô hình hóa điều này, chúng ta có thể sử dụng phân phối xác suất xen kẽ, thường dựa trên phân phối Poisson. Điều này sẽ dẫn đến biểu đồ “Hockey stick” (đường màu xanh) vì các đợt nổ poisson sẽ gây ra một số độ trễ khi xếp hàng (công suất tối đa) ngay cả khi tốc độ trung bình thấp hơn mức tối ưu. Điều này có lợi cho chúng tôi vì chúng tôi có thể thấy hệ thống xử lý mức tải cao như thế nào và hệ thống phục hồi nhanh như thế nào khi tải trở lại bình thường.
- Giai đoạn khởi động
Điểm cuối cùng cần xem xét là khi nào thì bắt đầu measure. Người ta thường muốn hệ thống có đầy đủ các giao dịch trước khi bắt đầu; nếu không, độ trễ khởi động sẽ được measure. Điều này lý tưởng nhất nên được thực hiện bằng cách đo độ trễ trong giai đoạn khởi động cho đến khi các phép đo tuân theo phân phối dự kiến.
Làm thế nào để so sánh
Khó khăn cuối cùng là so sánh các triển khai khác nhau của hệ thống trên cơ sở giữa các ứng dụng. Một lần nữa, khó khăn là độ trễ và thông lượng phụ thuộc lẫn nhau, do đó có thể khó tạo ra biểu đồ thông lượng/số lượng node hợp lý. Thay vì chỉ đẩy từng hệ thống đến thông lượng tối đa của nó (trong đó độ trễ là vô nghĩa), cách tiếp cận tốt nhất là xác định Mục tiêu cấp độ dịch vụ (SLO) và đo lường thông lượng tại thời điểm này. Vẽ một đường nằm ngang tại biểu đồ thông lượng/độ trễ giao với trục Latency tại SLO và lấy mẫu các điểm, có một cách hay để hình dung điều này.
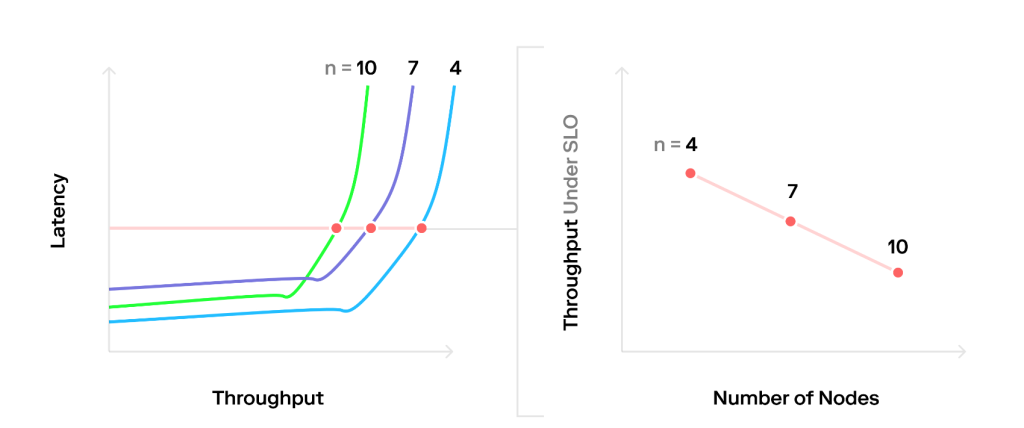
Nếu một hoạt động của hệ thống được cung cấp dưới mức dự phòng, một loạt yêu cầu không mong muốn sẽ khiến hệ thống đạt đến trạng thái bão hòa hoàn toàn, dẫn đến bùng nổ độ trễ và vi phạm SLO rất nhanh. Về bản chất, hoạt động sau điểm bão hòa là trạng thái cân bằng không ổn định. Kết quả là, có hai điểm cần xem xét:
1/ Cung cấp quá mức hệ thống của bạn. Về bản chất, hệ thống nên hoạt động dưới điểm bão hòa để các đợt bùng nổ trong phân phối giữa các điểm đến được hấp thụ, thay vì dẫn đến độ trễ gia tăng.
2/ Nếu bạn có chỗ trong SLO của mình, hãy tăng kích thước batch. Điều này sẽ thêm tải trên đường dẫn quan trọng của hệ thống thay vì độ trễ hàng đợi và mang lại cho bạn thông lượng cao hơn để đổi độ trễ cao hơn mà bạn đang tìm kiếm.
Làm thế nào để đo một load lớn?
Khi load cao, việc cố gắng truy cập đồng hồ cục bộ và thêm dấu thời gian cho mọi giao dịch đến trên hệ thống có thể dẫn đến kết quả sai lệch. Thay vào đó, có hai lựa chọn khả thi hơn. Phương pháp đầu tiên và đơn giản nhất là lấy mẫu các giao dịch; ví dụ: có thể có một con số kỳ diệu trong một số giao dịch là giao dịch duy nhất mà khách hàng hẹn giờ. Sau thời gian cam kết, bất kỳ ai cũng có thể kiểm tra chuỗi khối để xác định thời điểm các giao dịch này được thực hiện và do đó tính toán độ trễ của chúng. Ưu điểm chính của phương pháp này là nó không can thiệp vào phân phối giữa các điểm đến. Tuy nhiên, nó có thể được coi là “hacky” vì một số giao dịch phải được sửa đổi.
Một cách tiếp cận có hệ thống hơn sẽ là có hai bộ tạo load. Đầu tiên là bộ tạo tải chính, tuân theo phân bố Poisson. Trình tạo yêu cầu thứ hai đo độ trễ và có tải thấp hơn nhiều; hãy nghĩ về nó như một máy khách duy nhất so với phần còn lại của hệ thống. Ngay cả khi hệ thống gửi lại phản hồi cho mọi yêu cầu (như một số hệ thống thực hiện, chẳng hạn như cửa hàng KV), chúng tôi có thể dễ dàng gửi tất cả phản hồi tới trình tạo tải và chỉ đo độ trễ từ trình tạo yêu cầu. Phần khó khăn duy nhất là phân phối giữa các điểm đến thực tế là tổng của hai biến ngẫu nhiên; tuy nhiên, tổng của hai phân phối Poisson vẫn là một phân phối Poisson, vì vậy phép toán không khó lắm.
Kết luận
Đo lường một hệ thống phân tán quy mô lớn là rất quan trọng để nhận ra các bottleneck và lập hồ sơ hành vi dự kiến khi bị căng thẳng. Chúng tôi hy vọng rằng bằng cách sử dụng các phương pháp trên, tất cả chúng ta có thể thực hiện bước đầu tiên hướng tới một ngôn ngữ chung, điều này cuối cùng sẽ dẫn đến các hệ thống blockchain phù hợp hơn với công việc chúng làm.
{kind=link}