
Về ZKML: ZKML (Zero Knowledge Machine Learning) là một công nghệ học máy kết hợp giữa chứng minh không hiểu biết (Zero-Knowledge Proofs) và các thuật toán học máy nhằm giải quyết vấn đề bảo vệ quyền riêng tư trong máy học.
Về khả năng tính toán phân tán: Khả năng tính toán phân tán đề cập đến việc phân rã một nhiệm vụ tính toán thành nhiều nhiệm vụ nhỏ hơn và giao những nhiệm vụ nhỏ này cho nhiều máy tính hoặc bộ xử lý khác nhau để thực hiện tính toán hiệu quả.
Kỷ nguyên của AI và Web3: Sự lan tràn tự do và tăng trưởng nhiễu động
Trong cuốn sách “Out of Control: The New Biology of Machines, Society, and the Economy”, Kevin Kelly từng đề xuất một hiện tượng: Tổ ong sẽ tiến hành các quyết định bầu cử thông qua việc “nhảy múa theo nhóm” (group dance) dựa trên quản lý phân tán, và toàn bộ tổ ong sẽ tuân theo quy định của “group dance” được bầu chọn. Đây cũng là cái được gọi là “linh hồn của tổ ong” được đề cập bởi Maurice Maeterlinck – mỗi con ong có thể đưa ra quyết định riêng của mình, hướng dẫn những con ong khác xác nhận, và quyết định cuối cùng thực sự là sự lựa chọn của cả nhóm.

Định luật tăng nhiễu động (entropy increase) và sự tăng cường không tuần tự đều tuân theo định luật nhiệt động học, và hình ảnh hóa lý thuyết trong vật lý là đặt một số phân tử vào một hộp trống và tính toán hồ sơ phân bố cuối cùng. Đối với con người, đám đông được tạo ra bởi thuật toán có thể hiển thị định luật của cả nhóm mặc dù có sự khác biệt tư duy cá nhân. Đám đông bị hạn chế trong một hộp trống do các yếu tố như tuần suất, và cuối cùng sẽ đưa ra quyết định đồng thuận.
Tất nhiên, quy tắc nhóm có thể không chính xác, nhưng ý kiến của những người đứng đầu có thể đại diện cho sự đồng thuận và tạo ra sự đồng thuận một mình là những cá nhân vượt trội tuyệt đối. Nhưng trong hầu hết các trường hợp, đồng thuận không đòi hỏi sự chấp nhận hoàn toàn và vô điều kiện của tất cả mọi người, mà chỉ đòi hỏi nhóm người đại diện có một định danh chung.
Chúng ta không thảo luận ở đây liệu AI có dẫn dắt con người đến sai lầm hay không. Trên thực tế, đã có nhiều cuộc tranh luận về vấn đề này, cho dù đó là lượng lớn “rác thải” được tạo ra bởi các ứng dụng trí tuệ nhân tạo đã làm “ô nhiễm tính xác thực” của dữ liệu mạng, hay vì quyết định nhóm dẫn đến một số tình huống nguy hiểm hơn.
Lĩnh vực AI sinh ra đã có tính độc quyền. Ví dụ, việc đào tạo và triển khai các model lớn đòi hỏi một lượng lớn tài nguyên tính toán và dữ liệu, nhưng chỉ có một số nhỏ các doanh nghiệp và tổ chức có những điều kiện này. Những hàng trăm triệu dữ liệu này được coi là kho báu bởi từng chủ sở hữu độc quyền, không chia sẻ dữ liệu, thậm chí truy cập chéo cũng không đươc phép.
Điều này đã gây ra sự lãng phí dữ liệu, khả năng tận dụng dữ liệu. Mỗi dự án trí tuệ nhân tạo quy mô lớn phải thu thập dữ liệu người dùng lặp đi lặp lại, và cuối cùng là người chiến thắng ăn tất – cho dù đó là sáp nhập và thâu tóm hoặc bán hàng, mở rộng các dự án cá nhân khổng lồ. Đây là thuyết Đồng thuận cưỡng bức.
Nhiều người nói rằng AI và Web3 là hai khái niệm hoàn toàn khác nhau và không có sự liên kết – điều này chỉ đúng một nửa, đó là hai chiều hướng công nghệ khác nhau, nhưng nửa sau lại không đúng vì web3 có lợi thế về việc phân phối quyền hạn cho user để hạn chế sự độc quyền của trí tuệ nhân tạo, và tận dụng công nghệ trí tuệ nhân tạo để thúc đẩy hình thành cơ chế đồng thuận phi tập trung một cách tự nhiên.
Kết luận: Hãy để trí tuệ nhân tạo hình thành một cơ chế đồng thuận phi tập trung thực sự.
Bản chất của trí tuệ nhân tạo nằm trong chính con người, và máy móc và model AI chỉ là sự phỏng đoán và bắt chước tư duy của con người. Việc phân loại model thành các nhóm người thực chất khá trừu tượng, bởi vì những hành động suy nghĩ của mỗi cá thể ngoài đời thực vẫn có sự khác nhau rất lớn. Nhưng model AI sử dụng dữ liệu khổng lồ để học và điều chỉnh, và cuối cùng có thể mô phỏng thành các model nhóm hiệu quả.
Ví dụ, đối với một dự án DAO, nếu cơ chế quản trị được thực hiện, nó sẽ tác động đến hiệu suất của DAO. Nguyên nhân vì việc tạo một cuộc bỏ phiếu đồng thuận tốn chi phí nhiều: bỏ phiếu, thống kê và các hoạt động liên quan khác. Nếu việc quản trị của DAO được thực hiện bằng model AI và tất cả dữ liệu thu thập được từ mọi người trong DAO, thì quyết định đầu ra sẽ thực sự gần với kết quả bỏ phiếu đồng thuận thông thường.
Tuy nhiên, đừng vội đánh giá những kết quả mà mô hình đồng thuận có thể tạo ra là tốt hay xấu, bởi vì các sự cố về đồng thuận nhóm gây hậu quả tiêu cực không chỉ xảy ra một hoặc hai lần.
Đồng thuận nhóm của một mô hình duy nhất có thể được đào tạo theo kế hoạch trên, nhưng vẫn chỉ có thể thể hiện một phần ý kiến của các cá nhân độc lập. Nếu có một hệ thống trí tuệ tập thể để hình thành một trí tuệ nhân tạo nhóm, mỗi mô hình trí tuệ nhân tạo trong hệ thống này sẽ làm việc cùng nhau để giải quyết các vấn đề phức tạp.
Đối với những tập hợp nhỏ, bạn có thể xây dựng một hệ sinh thái độc lập, hoặc hình thành một tập hợp hợp tác với các tập hợp khác để đáp ứng sức mạnh tính toán siêu lớn hoặc giao dịch dữ liệu hiệu quả hơn và với chi phí thấp hơn. Nhưng lại có vấn đề khác. Hiện trạng giữa các cơ sở dữ liệu model khác nhau hoàn toàn không đáng tin cậy và xung đột với nhau – đây chính là nơi các thuộc tính tiêu biểu của Blockchain giao nhau: tính Trustless, các model trí tuệ nhân tạo thực sự phân tán, bảo mật.
Một bộ trí não AI toàn cầu có thể khiến những mô hình thuật toán trí tuệ nhân tạo ban đầu độc lập và chức năng đơn lẻ hợp tác với nhau, thực hiện quá trình thuật toán thông minh phức tạp bên trong và hình thành mạng lưới đồng thuận nhóm phân tán có thể tiếp tục phát triển. Điều này cũng là ý nghĩa lớn nhất của sự hỗ trợ của trí tuệ nhân tạo cho Web3.
Quyền riêng tư và Độc quyền dữ liệu? Kết hợp giữa ZK và Machine Learning
Con người phải thực hiện các biện pháp phòng ngừa đích danh để chống lại những hành vi nguy hiểm của AI hoặc bảo vệ quyền riêng tư/sự đe dọa độc quyền dữ liệu.
Vấn đề cốt lõi là chúng ta không biết kết luận được đưa ra như thế nào. Tương tự, người vận hành mô hình cũng không có ý định trả lời câu hỏi này. Và đối với sự kết hợp của bộ não AI toàn cầu mà chúng tôi đã đề cập ở trên, việc giải quyết vấn đề này càng cần thiết hơn, nếu không sẽ không có bên nào sẵn lòng chia sẻ thật lòng với người khác.
ZKML (Zero Knowledge Machine Learning) là một công nghệ sử dụng chứng minh không hiểu biết cho học máy. Chứng minh không hiểu biết (ZKP), tức là người chứng minh có thể thuyết phục người xác minh về tính xác thực của dữ liệu mà không tiết lộ dữ liệu cụ thể.
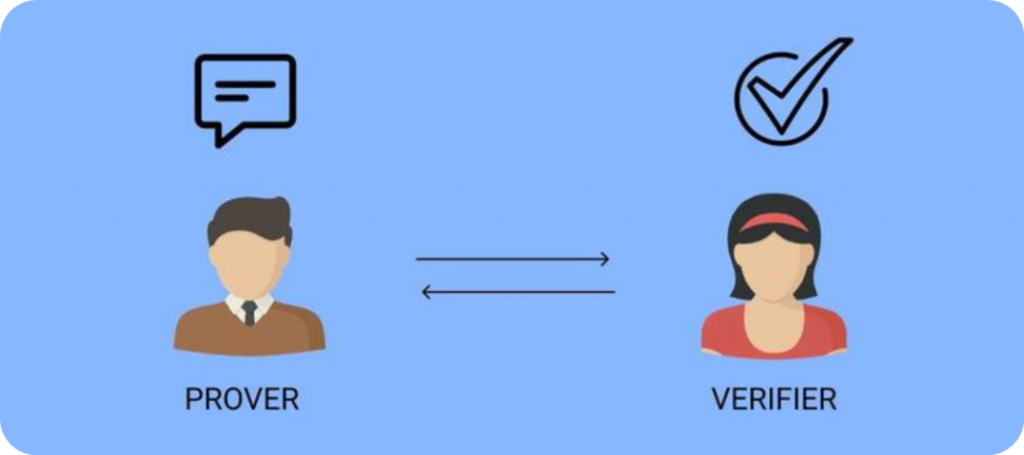
Cùng xem một ví dụ lý thuyết. Hãy xem xét một bảng Sudoku chuẩn 9×9. Điều kiện hoàn thành là điền các số từ 1 đến 9 vào chín lưới sao cho mỗi số chỉ xuất hiện một lần trong mỗi hàng, cột và lưới con. Vậy làm sao người sắp xếp câu đố này có thể chứng minh cho người thách đấu rằng Sudoku có một giải pháp mà không tiết lộ đáp án?
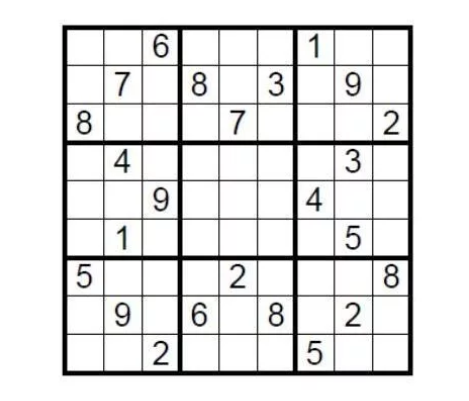
Bạn chỉ cần che đi các ô còn trống bằng đáp án và sau đó yêu cầu người thách đấu ngẫu nhiên chọn một vài hàng hoặc cột, xáo trộn tất cả các số và xác minh rằng chúng đều là từ một đến chín. Đây là một cách triển khai đơn giản của chứng minh không hiểu biết.
Công nghệ chứng minh không hiểu biết có ba đặc điểm là tính đầy đủ, tính chính xác và không hiểu biết, nghĩa là nó chứng minh kết luận mà không tiết lộ bất kỳ chi tiết nào. Nguồn gốc của công nghệ này có thể phản ánh tính đơn giản. Trong ngữ cảnh của mã hóa đồng dạng, độ khó của việc xác minh thấp hơn đáng kể so với độ khó của việc tạo chứng minh.
Học máy là việc sử dụng thuật toán và mô hình để cho phép các hệ thống máy tính học và cải thiện từ dữ liệu. Học từ kinh nghiệm thông qua tự động hóa cho phép hệ thống thực hiện tự động các nhiệm vụ như dự đoán, phân loại, gom cụm và tối ưu hóa dựa trên dữ liệu và mô hình.
Về mặt cốt lõi, học máy là về việc xây dựng các mô hình học từ dữ liệu và thực hiện dự đoán và quyết định tự động. Xây dựng những mô hình này thường đòi hỏi ba yếu tố quan trọng: bộ dữ liệu, thuật toán và đánh giá mô hình. Bộ dữ liệu là nền tảng của học máy và chứa các mẫu dữ liệu để huấn luyện và kiểm tra các mô hình học máy. Thuật toán là trái tim của các mô hình học máy, xác định cách mô hình học và dự đoán từ dữ liệu. Đánh giá mô hình là một phần quan trọng của học máy, được sử dụng để đánh giá hiệu suất và độ chính xác của mô hình, và quyết định xem mô hình có cần được tối ưu hóa và cải thiện hay không.
Sức mạnh tính toán phân tán: Câu chuyện mới mẻ, nửa thực nửa ảo
Mạng lưới tính toán phân tán luôn là một chủ đề được nhắc đến đến nhiều trong cộng đồng mã hóa. Sau tất cả, các mô hình trí tuệ nhân tạo lớn đòi hỏi sức mạnh tính toán đáng kinh ngạc, và mạng lưới tính toán tập trung không chỉ gây lãng phí tài nguyên mà còn tạo thành một sự độc quyền đáng kể – số lượng GPU là điều quyết định tất cả.
Bản chất của một mạng lưới tính toán phân tán là kết hợp các tài nguyên tính toán phân tán ở các vị trí và trên các thiết bị khác nhau. Những lợi ích chính thường được nhắc đến là: cung cấp khả năng tính toán phân tán, giải quyết các vấn đề về quyền riêng tư, nâng cao độ tin cậy và đáng tin cậy của các mô hình trí tuệ nhân tạo, hỗ trợ triển khai và vận hành nhanh chóng trong các kịch bản ứng dụng khác nhau, và cung cấp các phương án lưu trữ và quản lý dữ liệu phi tập trung. Đúng vậy, thông qua sức mạnh tính toán phân tán, bất kỳ ai cũng có thể chạy các mô hình trí tuệ nhân tạo và thử nghiệm chúng trên các tập dữ liệu thực tế trên chuỗi từ người dùng trên toàn thế giới, từ đó, họ có thể tận hưởng dịch vụ tính toán linh hoạt, hiệu quả và giá thấp hơn.
Đồng thời, sức mạnh tính toán phân tán cũng có thể giải quyết các vấn đề về quyền riêng tư bằng cách tạo ra framework chặt chẽ hơn để bảo vệ sự an toàn và quyền riêng tư của dữ liệu người dùng. Nó cũng cung cấp một quy trình tính toán minh bạch và xác thực, nâng cao tính đáng tin cậy và đáng tin cậy của các mô hình trí tuệ nhân tạo và cung cấp tài nguyên tính toán linh hoạt và có khả năng mở rộng cho việc triển khai và vận hành nhanh chóng trong các kịch bản ứng dụng khác nhau.
Chúng ta xem xét quá trình huấn luyện mô hình từ một quy trình tính toán tập trung hoàn chỉnh. Các bước thông thường được chia thành: chuẩn bị dữ liệu, phân đoạn dữ liệu, truyền dữ liệu giữa các thiết bị, huấn luyện song song, tổng hợp gradient, cập nhật tham số, đồng bộ hóa và huấn luyện lặp lại. Trong quá trình này, ngay cả khi phòng máy tính tập trung sử dụng cụm thiết bị tính toán hiệu năng cao và chia sẻ nhiệm vụ tính toán thông qua kết nối mạng tốc độ cao, chi phí giao tiếp cao đã trở thành một trong những hạn chế lớn nhất của mạng lưới tính toán phân tán.
Do đó, mặc dù mạng lưới tính toán phân tán có nhiều ưu điểm và tiềm năng, con đường phát triển vẫn gian nan theo chi phí giao tiếp hiện tại và khó khăn thực tế sau khi hoạt động. Để thực hiện một mạng lưới tính toán phân tán, cần vượt qua nhiều vấn đề kỹ thuật thực tế, đồng thời phải đảm bảo độ tin cậy và bảo mật của các Nodes. Làm thế nào để quản lý và lập lịch tài nguyên tính toán phân tán một cách hiệu quả, hay làm thế nào để đạt được việc truyền dữ liệu và giao tiếp hiệu quả, v.v.?
Kết luận: Hy vọng thực tế hay ý tưởng viển vông
Trở lại thực tế kinh doanh hiện tại, câu chuyện về sự tích hợp sâu sắc của trí tuệ nhân tạo AI và Web3 nghe rất hay, nhưng vấn đề tài chính và user được đặt ra cho thấy đây là một hành trình đổi mới cực kỳ khó khăn, trừ khi dự án có thể như OpenAI, vừa có một người bảo trợ tài chính mạnh mẽ vừa nổi tiếng, nếu không, các chi phí nghiên cứu và phát triển vô tận cùng với mô hình kinh doanh chưa rõ ràng sẽ hoàn toàn làm câu chuyện trên tan nát.
Cho dù đó là trí tuệ nhân tạo hay Web3, cả hai đều đang ở giai đoạn phát triển rất sớm, giống như “bong bóng Internet” vào cuối thế kỷ trước, và chỉ sau gần mười năm nữa, thời kỳ vàng thực sự mới chính thức khởi đầu.
Tương tự, điều đó cũng đúng cho Web3+AI. Chúng ta đã xác định đúng đường đi phía trước, và những phần còn lại sẽ để lại cho thời gian trả lời.
{kind=link}